
Derin Takviyeli Öğrenme (Deep Reinforcement Learning), yapay zekanın en havalı ve belki de en karmaşık alt dallarından biri. "Kuralları öğren, ödülü kap!" temalı bu teknoloji, makinelerin çevreleriyle etkileşime girerek kendi kendine öğrenmesini sağlar. Gelin, bu büyüleyici alanı biraz daha derinlemesine inceleyelim.
Derin Takviyeli Öğrenmenin Temelleri
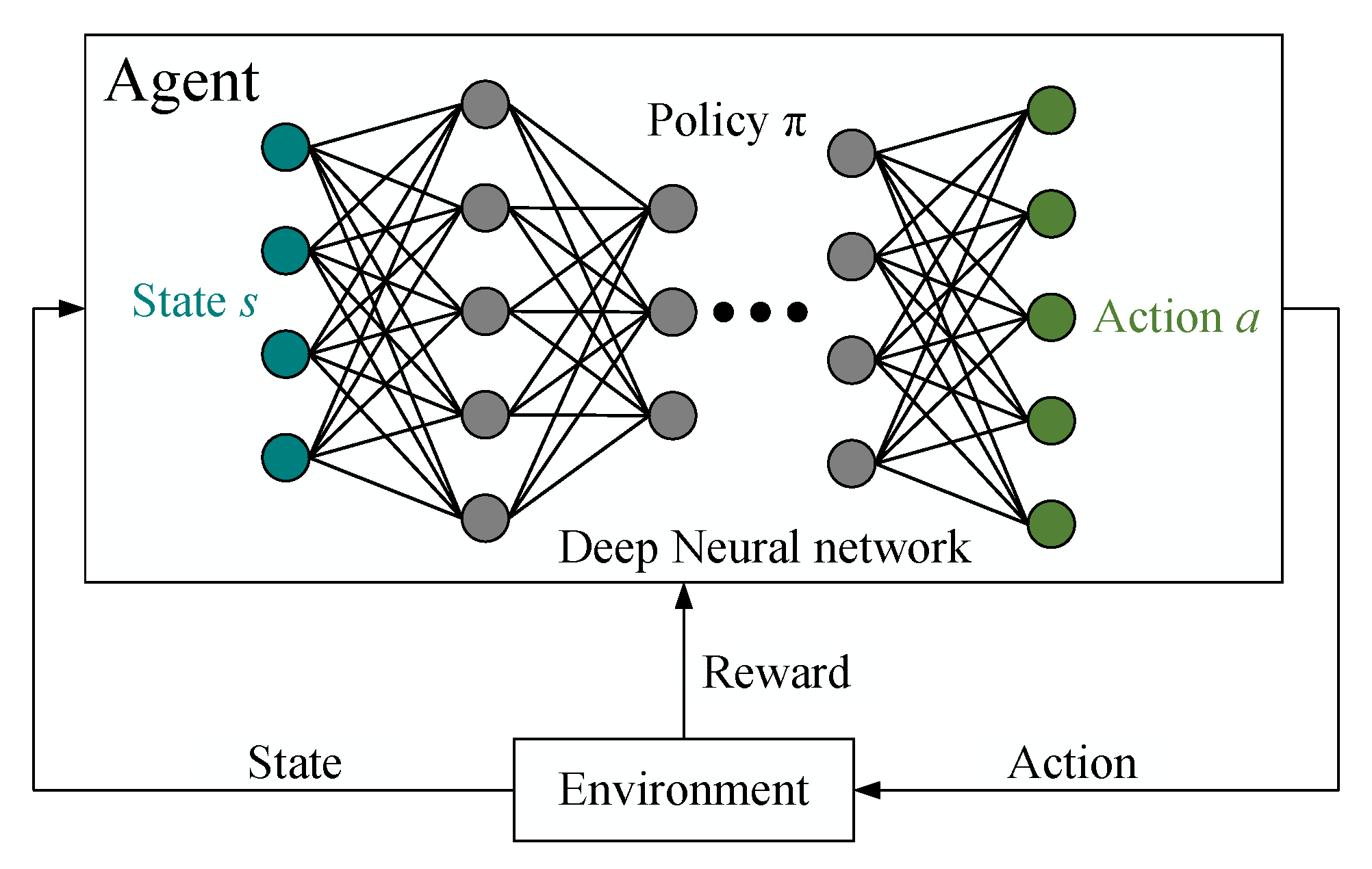
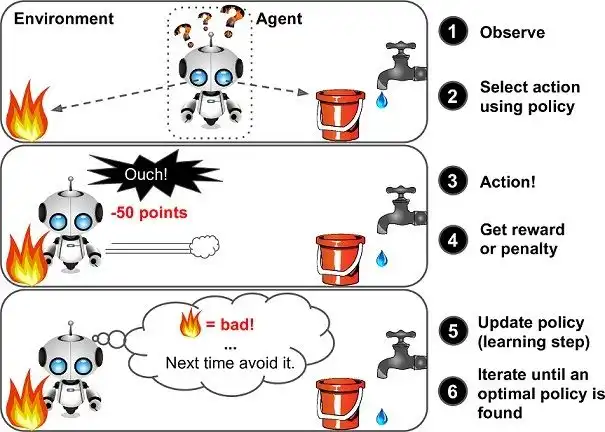
Takviyeli öğrenme, bir ajan (yapay zeka) ve bir çevre (dünya) arasındaki etkileşimler üzerine kuruludur. Ajan, belirli bir durumdayken (state) bir eylem (action) gerçekleştirir ve bunun sonucunda bir ödül (reward) alır. Amaç, ajan için en yüksek ödülü getirecek stratejiyi (policy) öğrenmektir. Derin öğrenme teknikleri ile bu süreç daha da güçlendirilir:
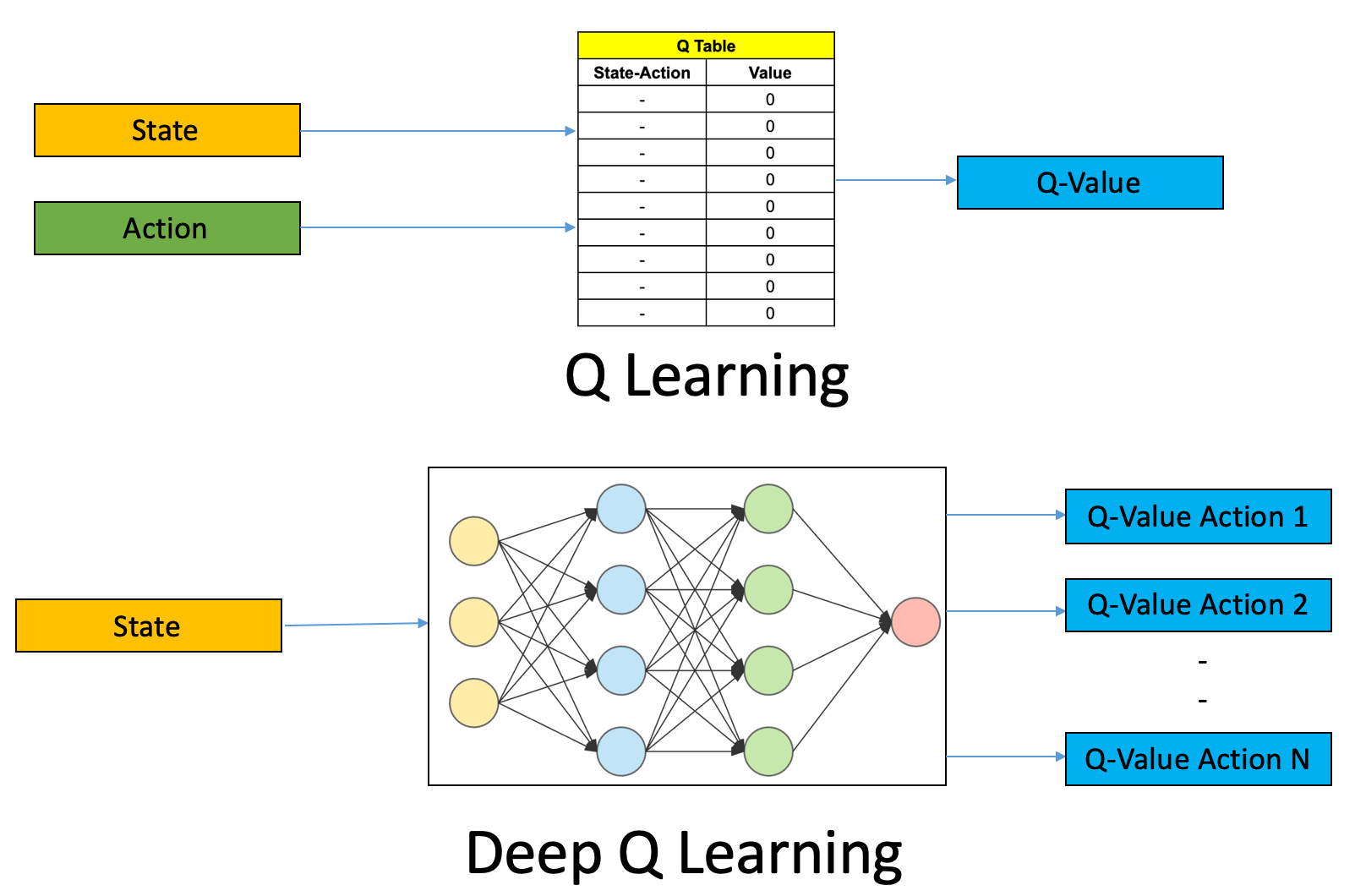
- Q-Öğrenme: Ajan, her duruma ve eyleme bağlı olarak Q-değerleri (beklenen ödül) hesaplar ve bu değerlere dayanarak en iyi eylemi seçer.
- Poliçe Gradyanı: Ajan, doğrudan bir poliçeyi optimize ederek hareket eder, böylece her eylemin ödül katkısını maksimize eder.
- DQN (Deep Q-Networks): Derin öğrenme ağları, Q-değerlerini tahmin etmek için kullanılır, bu da karmaşık durum-uzaylarını daha iyi ele almayı sağlar.
Günlük Hayatta Derin Takviyeli Öğrenme
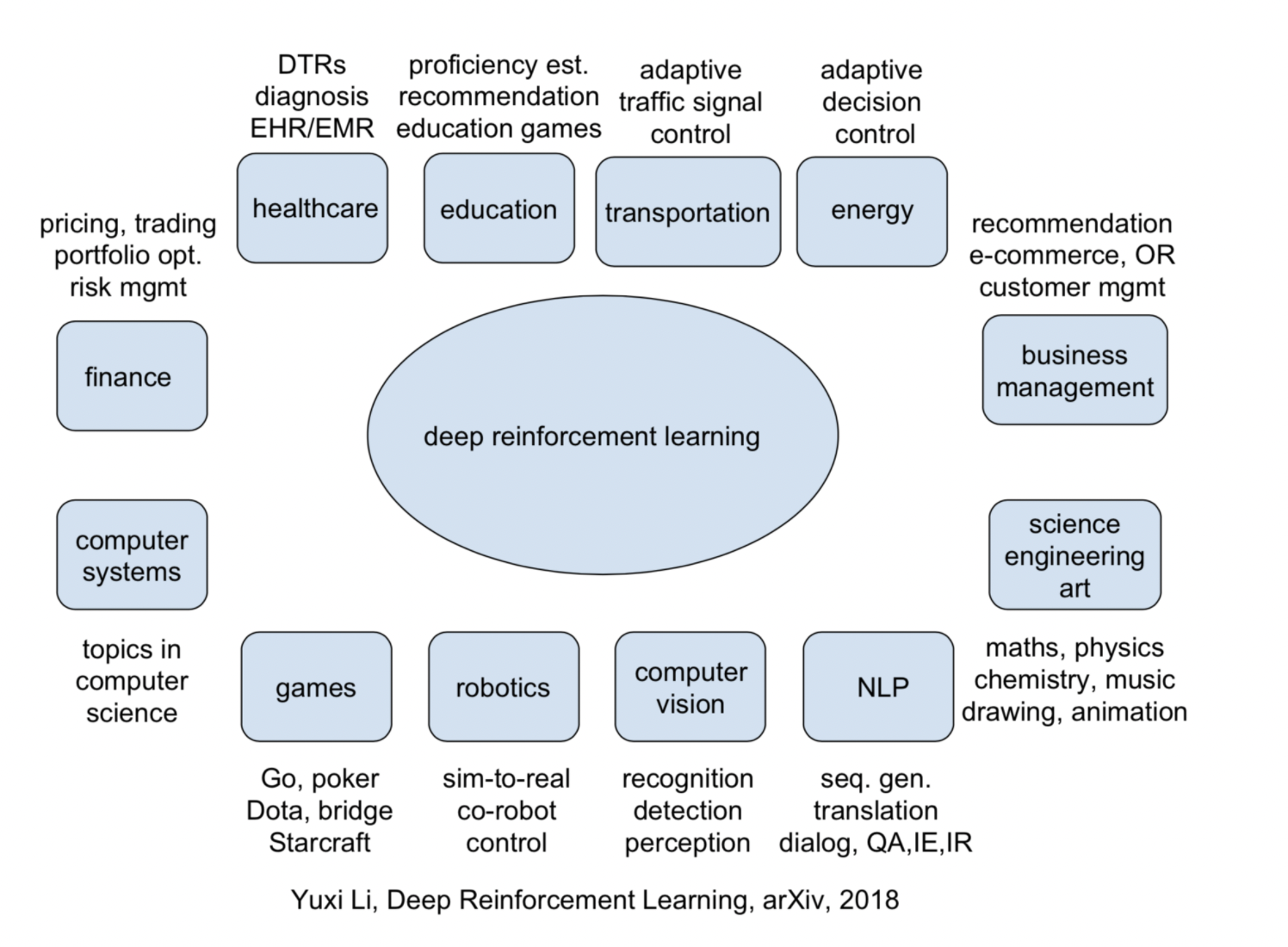
Derin Takviyeli Öğrenme, birçok alanda devrim yaratıyor. İşte bazı çarpıcı örnekler:
- Oyunlar: Yapay zekanın Go gibi karmaşık oyunlarda insanları yenmesi, bu teknolojinin gücünü gösteriyor. DeepMind'in AlphaGo'su, takviyeli öğrenmenin ne kadar ileri gidebileceğinin bir örneği.
- Robotik: Robotlar, çevrelerini keşfederek ve öğrenerek, daha verimli ve otonom hale geliyor. Özellikle, dinamik ve öngörülemeyen ortamlarla başa çıkmak için bu teknoloji kullanılıyor.
- Finans: Otomatik ticaret sistemleri, piyasadaki hareketleri öğrenerek daha karlı stratejiler geliştirebilir.
Gerçekler ve Zorluklar
Her şey güllük gülistanlık değil elbette. Derin Takviyeli Öğrenme, birçok zorluk ve sınırlama ile karşı karşıya:
- Veri İhtiyacı: Büyük miktarda veri ve simülasyon gerektirir, bu da hesaplama kaynakları açısından maliyetlidir.
- Stabilite Sorunları: Eğitim süreci bazen kararsız olabilir ve ajan beklenmedik davranışlar sergileyebilir.
- Genelleme: Öğrenilen stratejilerin farklı ve yeni durumlara genelleştirilebilmesi zor olabilir.
Derin Takviyeli Öğrenmenin Geleceği

Bu teknolojinin geleceği oldukça parlak. İşte bazı öngörüler:
- Genelleştirilmiş Ajanlar: Birden fazla görevde başarılı olabilecek çok yetenekli ajanlar geliştirilmesi hedefleniyor.
- İnsan-Makine İş birliği: İnsanlarla daha iyi etkileşim kurabilen ve işbirliği yapabilen yapay zekalar geliştirilecek.
- Daha Verimli Algoritmalar: Hesaplama ve veri gereksinimlerini azaltan daha verimli algoritmalar geliştiriliyor.
Eleştirel Bir Bakış
Takviyeli öğrenme, büyüleyici ve potansiyel dolu olsa da, bazı eleştirilerden kaçamıyor. Özellikle veri mahremiyeti ve etik konularında ciddi endişeler var. Ajanların öğrendikleri stratejilerin şeffaf olmaması ve bazen beklenmedik sonuçlar doğurması, güvenlik ve güvenilirlik konularında soru işaretleri yaratıyor.
Sonuç
Derin Takviyeli Öğrenme, yapay zekanın en dinamik ve heyecan verici alanlarından biri. Çeşitli uygulama alanlarında hayatımızı etkileyen bu teknoloji, gelecekte daha da büyük yenilikler vaat ediyor. Ancak, bu teknolojiyi eleştirel bir bakış açısıyla değerlendirmek ve etik sorulara yanıt aramak her zamankinden daha önemli. Unutmayın, yapay zeka ne kadar akıllı olursa olsun, insani değerlerimizi ve etik anlayışımızı korumak bizim sorumluluğumuzda.
Yorumlar (0)

Kategoriler
Son Gönderiler


Yapay Zeka Destekli Tarım: Geleceğin ...
28/11/2024
Yapay Zeka Eğitiminde Temel Matematik: ...
25/02/2025
Unity Shader Graph Kullanımı: ...
15/03/2025



